

Varför syns inte min sida i Googles sökresultat?
Funderar du på varför din sida inte syns i sökresultatet? Här är ett antal kontroller du kan göra för att lösa problemet.

Det finns en mängd olika anledningar till varför du inte ser din sida i det organiska sökresultatet. Men innan du börjar spendera mängder av tid och pengar på att försöka lösa problemet genom att starta ett seo-projekt, så ska du börja med att kolla på de vanligaste anledningarna till att Google har problem att hitta eller förstå din webbsida enligt Topdog.
Nedan har du en lista med de vanligaste anledningarna till att Google inte kan hitta din sida. Skulle det vara så att du inte kan hitta en lösning till dina bekymmer så kommentera artikeln för direkt hjälp av andra läsare och/eller mig.
1. Google har inte indexerat din sida än
Titta på cachen. Om din sida blev lanserad för, säg en eller två dagar sedan, samtidigt som du inte är Amazon eller CNN, är det högst troligen så att Google inte har letat sig fram till din sida än. Det snabbaste sättet att se till att din sida blir indexerad är att lägga till den i deras Fetch-verktyg i Sökkontrollerna. För att använda Googles cache, skriv såhär i Google sökfält: cache:http://exempel.nu/
2. Google kan inte hitta fram till din sida
Länkar du till den här sidan från andra sidor? Finns den i din sitemap? Om du har svarat nej på båda dessa frågor så kan det vara så att du har skapat en sida som befinner sig i ingenmansland.
3. Noindex är kvar i koden på din webbsida
Vad är en noindex metatag? Någon har implementerat en instruktion till Google som säger att sökmotorn inte ska indexera sidan. Ta bort denna lilla detalj från sidan och det kan lösa dina problem. Läs mer om noindex här!
4. Det finns en exkludering i Robots.txt
Det kan gälla sidan, mappen eller hela domänen. Det är inte helt ovanligt att webbyrån glömmer ändra detta när de skickar en ny relase från din webbsida direkt från utvecklingsmiljön. Det är nämligen standard att inte låta Google indexera utvecklingsmiljön Om du blockerar hela sidan så kommer filen som du hittar under dindomän.se/robots.txt se ut så här:

5. Googlebot blir blockerad av robots.txt
Det finns väldigt få anledningar till att du skulle ha det här upplägget, men medan du ändå håller på att titta på mappar, sidor och hela domänen så koll om direktivet blockerar Googlebot. Skulle det vara så att något är blockerat kan du kolla denna listan över ”useragents” för att se vilka botar som är blockerade
6. Länkarna som pekar till din sida är Nofollow.
Teoretiskt sett är det är ett ytterligare sätt att blockera Google från att hitta din sida. Nofollow är ett attribut som uppfanns av Matt Cutts för att användas på utlänkar från en sida som man inte vill ge cred för, tex om det är en annonslänk.
7. Canonical pekar till en annan sida
Rel=canonical används för att visa vilken url som är den viktiga urlen, den som skall visas i Google, när det finns flera likadana eller väldigt lika urlar. Det görs genom att samla värdet av alla dessa sidor till en och samma sida som då samtidigt visar den sida som ägaren av webbplatsen vill ska visas.
Så när en canonical på din blogg eller bland dina produkter pekar mot en annan sida så är det osannolikt att just den urlen eller hela din sajt kommer att visas i sökresultatet. Är det en specifik bloggpost eller produkt som inte syns så se till att rel=canonical refererar till samma sida, eller ta helt enkelt bort den om du inte kan ändra den.
8. Ditt innehåll är identiskt med en annan sida eller webbplats
I det här fallet som kommer Google helt säkert att indexera din sida, men om du inte ser någon organisk trafik så har din sida troligtvis uteslutits från Googles index, då innehållet redan fanns där. Det enklaste sättet att ta reda på om så är fallet är att ta kopiera fras på sju-åtta ord, från din webbsida, sätta det inom citationstecken och söka efter det. Om du får mängder av resultat i Google så har du för mycket duplicerat innehåll på din sida eller så har du tagit för mycket innehåll från någon annan (exempelvis produktbeskrivningar) och Google värderar därmed inte din sida som tillräckligt unik.
9. Ta bort URL i Webmaster Tools
Det är ganska osannolikt, men det kan vara så att någon har begärt att sidan ska tas bort. För att hitta den informationen så loggar du in i Webmaster Tools och går till Google Index – Remove URLs.
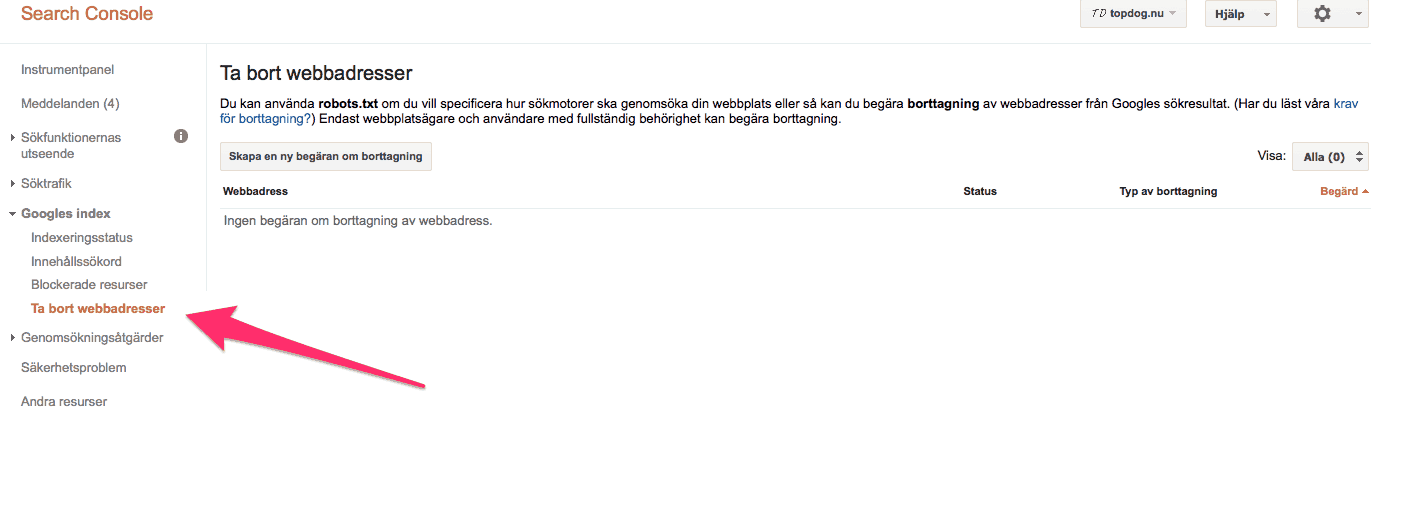
Där kommer du att hitta alla de URL:er som har begärts att bli borttagna. Om du endast hittar ”No URL removal requests” så kan du stryka den här punkten från listan som orsaken till att din sida inte dyker upp i sökresultatet.
Som lite extra information så kan du här också ”ta bort” din sida helt genom att skriva ”/”.
Genom att göra så här så tar du bort din sida för nya sökningar i 90 dagar. Oavsett om det gäller hela webbplatsen eller bara en sida så tar det alltid 90 dagar innan Google på nytt börjar crawla sidorna.
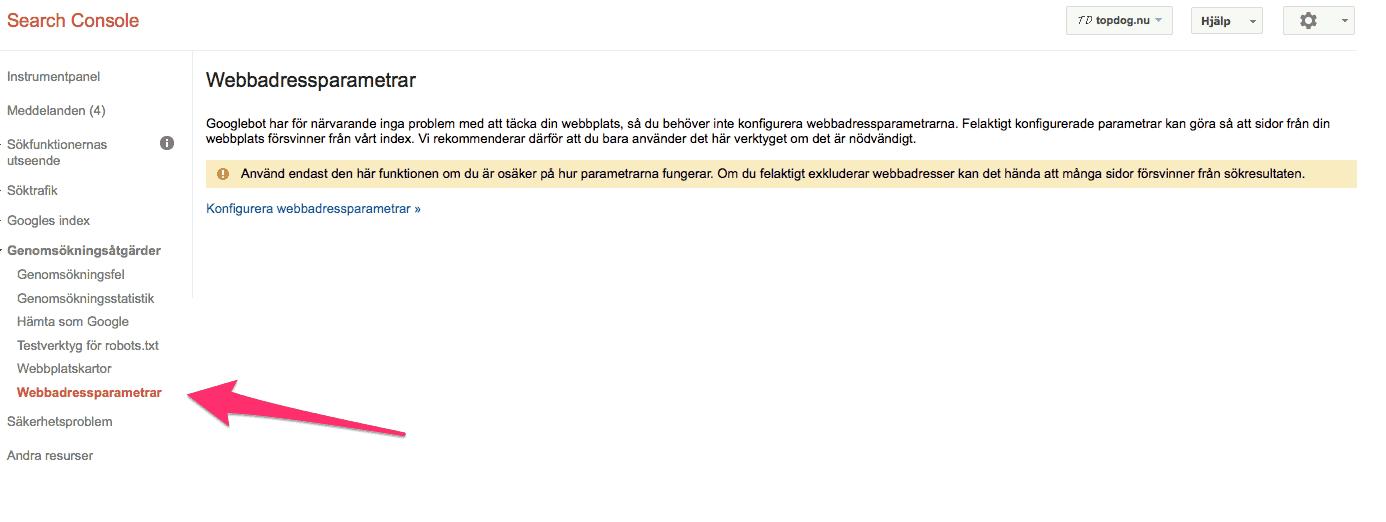
10. Om sidan har en parameter kan det betyda att den är märkt som crawl No URLs i Google Search Consol
Det här kan diagnostiseras genom att kolla om sidan inte dyker upp i Google, men gör det i andra sökmotorer. För att undersöka den saken ska du gå till Crawl-tabben i Webmaster Tools och i menyn välja ”URL Parameters”. Om du ser några ”No URLs” så se till att sidan som du vill ska synas inte har några sådana som styr den.

11. Någon typ av malware eller hackerattack
Google kommer då att ta bort sidor som är påverkade så de ej sprider smitta vidare till Googles användare. I Google search consol kommer du då att bli varnad genom ett meddelande och dessutom få mer specifik information i ”Security Issues” i vänstermenyn – Search Console.
12. Manuell penalisering på webbplatsen
Det här borde listas i din Search Console. Om det inte gör det så kolla på länkarna till den sidan och kolla om det är dussintals av länkar som inte har någon anledning till att länka till din sida. Förhoppningsvis får du upp en informationsruta som berättar att ”No manual webspam actions found”.
13. Förstörd pagination
Kanske är det så att du länkar till sidan som har problem med att indexeras, men att den länkas från page=2 som har blivit försatt med No index, nofollowed pagination, canonicalized pagination tillbaka till huvudkategorin. Eller så är sidorna blockerade av robots.txt eller i Webmaster Tools. Om det är det enda sättet att komma till den specifika produkten eller bloggposten så kan det här vara problemet.
Google har bra information om vad som är de vanligaste misstagen med rel=canonical, där just pagination är det första exemplet.
Google kan ibland vara riktigt frustrerande, och det kan vara så att ingen av ovanstående punkter kommer att lösa problemet. Om det är fallet så skicka en kommentar till det här inlägget så att fler människor kan se problemet och kanske hjälpa till med att lösa det.
Innehåll
- 1. google har inte indexerat din sida än
- 2. google kan inte hitta fram till din sida
- 3. noindex är kvar i koden på din webbsida
- 4. det finns en exkludering i robots.txt
- 5. googlebot blir blockerad av robots.txt
- 6. länkarna som pekar till din sida är nofollow.
- 7. canonical pekar till en annan sida
- 8. ditt innehåll är identiskt med en annan sida eller webbplats
- 9. ta bort url i webmaster tools
- 10. om sidan har en parameter kan det betyda att den är märkt som crawl no urls i google search consol
- 11. någon typ av malware eller hackerattack
- 12. manuell penalisering på webbplatsen
- 13. förstörd pagination

Christian Rudolf
VD och Sökmotorkonsult
Christian har +20 års av erfarenhet av SEO och digital marknadsföring. Denna erfarenhet inkluderar svåra segment som casino och finans men även globalt. Det som gör Christian bra på SEO är fokus på genomförande. Detta är det riktiga problemet inom SEO.